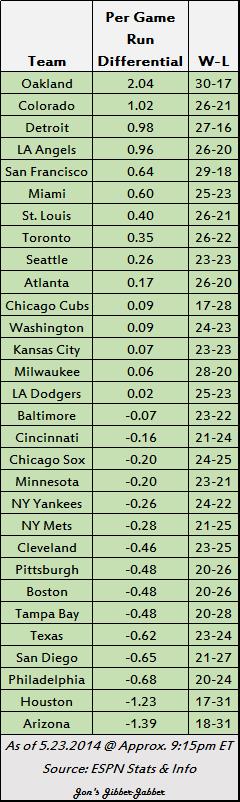
Today, I will post the first of several entries relating to a unique dataset that I’ve put together–a dataset that contains over 600 rows of data on a topic of great importance……………..superheroes and supervillains! Okay, analyzing superhero data may not be the most urgent matter that we as a society face, but:
1) I think that it is often useful to include entertaining applications when demonstrating what may otherwise be dry statistical methodology (though, admittedly, I sometimes find the “dry” statistics entertaining as well).
2) I find it fun to casually talk to friends about superheroes (especially those in recent movies) simply because, well, it’s just that: fun! And much like sabermetricians use statistics to challenge what is thought to be conventional baseball wisdom, I hope to use statistics to address pertinent topics relating to superheroes and supervillains (let’s call this discipline supermetrics?).
Setting the Stage
Before I get into the statistical analysis of the data, I must put a few things on the table.
1) Disclaimer I do not claim to be a superhero enthusiast, expert, or anything of the kind. I don’t think I have ever read a comic book in my life. I am, however, a fan of superhero movies (e.g., Man of Steel, The Dark Knight, Captain America, The Avengers, etc.) along with the television show, Arrow. So what does this tidbit have to do with anything? For one, with regard to my statistical analyses, it’s probably a good thing that I’m not a huge supporter of any given hero or villain. This should play a role in producing unbiased results. Additionally, my unfamiliarity with the comic book universe becomes a disadvantage in terms of data familiarity. Namely, I am fairly confident that I would not be able to recognize any superhero that is over- or underrated (more on the data below), making erroneous calculations more likely. With this in mind, if any comic book experts out there see any peculiar results, they are certainly welcome to leave a comment or drop me an email.
2) Data The data in the dataset that I will use to conduct my analyses come courtesy of the Superhero Database. This site houses a collection of information about 611 superheroes and villains. Each character (with data) is given a score between 0 and 100 (except in a few rare cases, where characters are deemed to be worthy of scores greater than 100) for six different traits: Intelligence, Strength, Speed, Durability, Power, and Combat. For example, here are the ratings for Batman:
| Intelligence |
Strength |
Speed |
Durability |
Power |
Combat |
| 100 |
18 |
27 |
42 |
37 |
100 |
Correction. Each character actually has two sets of these ratings. One such set is attributable to the creation of the website (the website was created to log and rate superheroes) while the other set is an average of user ratings. I chose to use the site’s ratings (the first set) because it allowed for a more complete dataset (many heroes and villains were not rated by users). In the event that the users rated the character and the site itself did not, I simply used the users’ ratings. After using this strategy, I came out with 440 superheroes/villains on which to perform analyses (171 subjects without usable ratings from either the site or its users).
I have one final note on the data. It is obviously highly subjective. When a human being is rating anything, there is always an element of subjectivity. Superheroes pose a particular challenge because they are fictional (so we are assigning subjective ratings to characters that were developed based on an author’s subjectivity). So please do not take the analyses too seriously, but certainly have fun critiquing and debating them! (Note: I do like how ratings can take on any discrete value between 0 and 100. This large range allows raters to address subtle differences among superheroes/villains.)
Visualizing Differences in Superhero Traits
The first items that I will present in analyzing this dataset are heatmaps.
Heroes
I created a non-random sample of superheroes to include big names. I did this using my opinions of which superheroes are popular and by surfing the web for lists of popular superheroes. After I had a list of about 20 heroes, I generated a heat matrix using R that color-coded the six attributes for each hero.
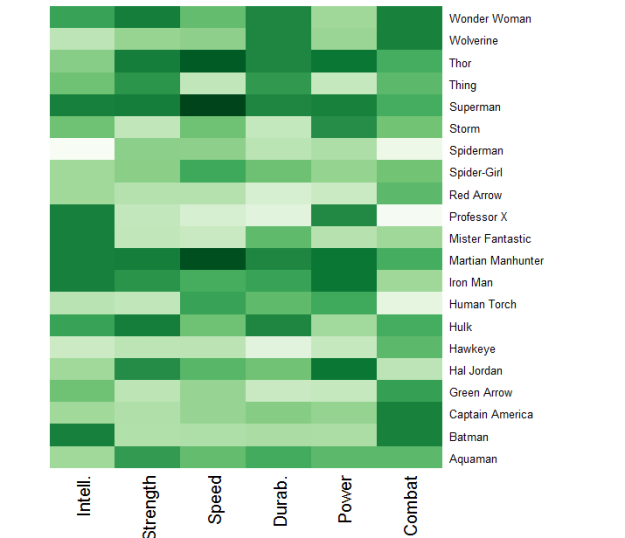
Superheroes and their ratings. A darker shade corresponds to a higher rating relative to peers.
I really like this form of visualization. One is able to view 126 individual data points in this graphic and I can assure you that it is easier to gain a grasp of the data using colors in the matrix rather than numeric values. Does anything stand out to you? Martian Manhunter, Superman, and Thor all have relatively high ratings across the board. And as we saw above, while Batman is exceptionally intelligent and excels in combat, he could use work in the other four departments.
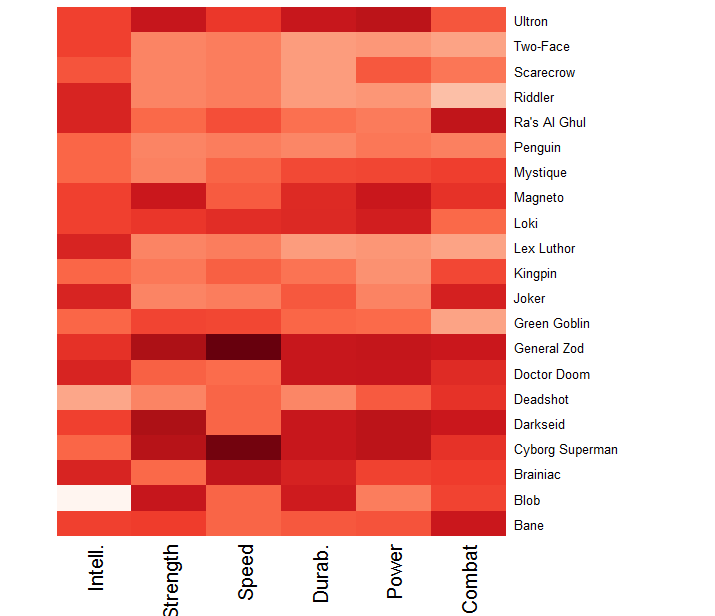
Villains
I replicated the heatmap visualization using popular supervillains in place of superheroes. (Note: This graphic is probably a bit biased toward Batman villains, because those are the most familiar to me and I felt compelled to include them!)
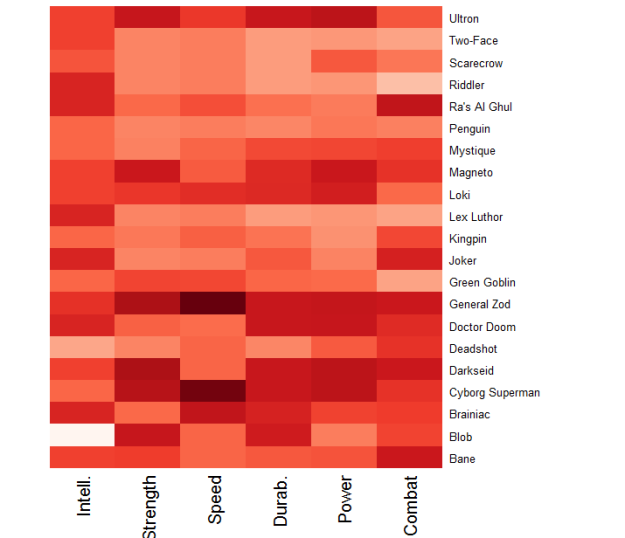
Supervillains and their ratings. A darker shade corresponds to a higher rating relative to peers.
Here we can see that General Zod–who you may have recently seen in Man of Steel— is, for lack of a better term, a beast. He possesses an attribute score of at least 94 in each of the six categories. Interestingly, it becomes apparent that many of the famous Batman villains (e.g., Joker, Penguin, Riddler, and Two-Face) rely on a high level of intellect to challenge Batman. Then, however, we have Ra’s Al Ghul and Bane; both villains possess extraordinary combat ratings.
Closing Remarks
This post was devoted to introducing the superhero/villain dataset with which I will be working in subsequent posts. Additionally, I took a first step in statistically analyzing the data by visualizing differences in characteristics among heroes and villains. I’d be interested to hear whether anything jumps out to you when studying those graphics!
In future posts, I aim to move beyond visualizing the data by applying various statistical methods to the data. Hopefully you find the superhero data and the relevant questions that can be addressed both fun and entertaining, but also of practical importance with regard to the statistical methods being employed.
******************************************************************************
Download the data (.xls): Superhero & Supervillain Data
R code:
#source used: http://flowingdata.com/2010/01/21/how-to-make-a-heatmap-a-quick-and-easy-solution/
#will need to install ggplot2 and RColorBrewer
#generate heatmap for select, non-random, heroes
super <- read.csv("~/Blog/select.csv", stringsAsFactors=FALSE) #read-in CSV file; insert appropriate path
super <- super[order(super$Name),] #sort heroes alphabetically
row.names(super) <- super$Name
super <- super[,3:8] #using these 6 columns for analysis
super_matrix <- data.matrix(super)
super_heatmap <- heatmap(super_matrix, Rowv=NA, Colv=NA,
col = colorRampPalette(brewer.pal(9,"Greens"))(1000), scale="column",
margins=c(5,10))
#generate heatmap for select, non-random, villains
vill <- read.csv("~/Blog/selectvill.csv", stringsAsFactors=FALSE) #read-in CSV file; insert appropriate path
vill <- vill[order(vill$Name),] #sort villains alphabetically
row.names(vill) <- vill$Name
vill <- vill[,3:8] #using these 6 columns for analysis
vill_matrix <- data.matrix(vill)
vill_heatmap <- heatmap(vill_matrix, Rowv=NA, Colv=NA,
col = colorRampPalette(brewer.pal(9,"Reds"))(1000), scale="column",
margins=c(5,10))